自动化模型选择和训练
预测大模型的基模型支持XGBoost、随机森林、支持向量机、高斯过程、梯度提升树等主流机器学习模型作为基模型;融合模型支持卷积神经网络CNN、全连接网络或者两者的结合。内置自动机器学习技术(AutoML),实现全自动的基模型选择和融合模型训练。
高泛化与高精度
预测大模型的自动学习能力可以适用于不同行业和领域中的不同任务;在具体任务中,可自适应构建不同基模型和融合模型,实现更高的精度。
复杂问题的建模能力
随着问题复杂度的增加,建模时所需要的输入维度增加。基于创新的架构和训练方法,预测大模型具有更强的复杂问题建模能力,支持千量级输入维度的建模,模型精度和建模能力相比传统方法具有明显的优势。
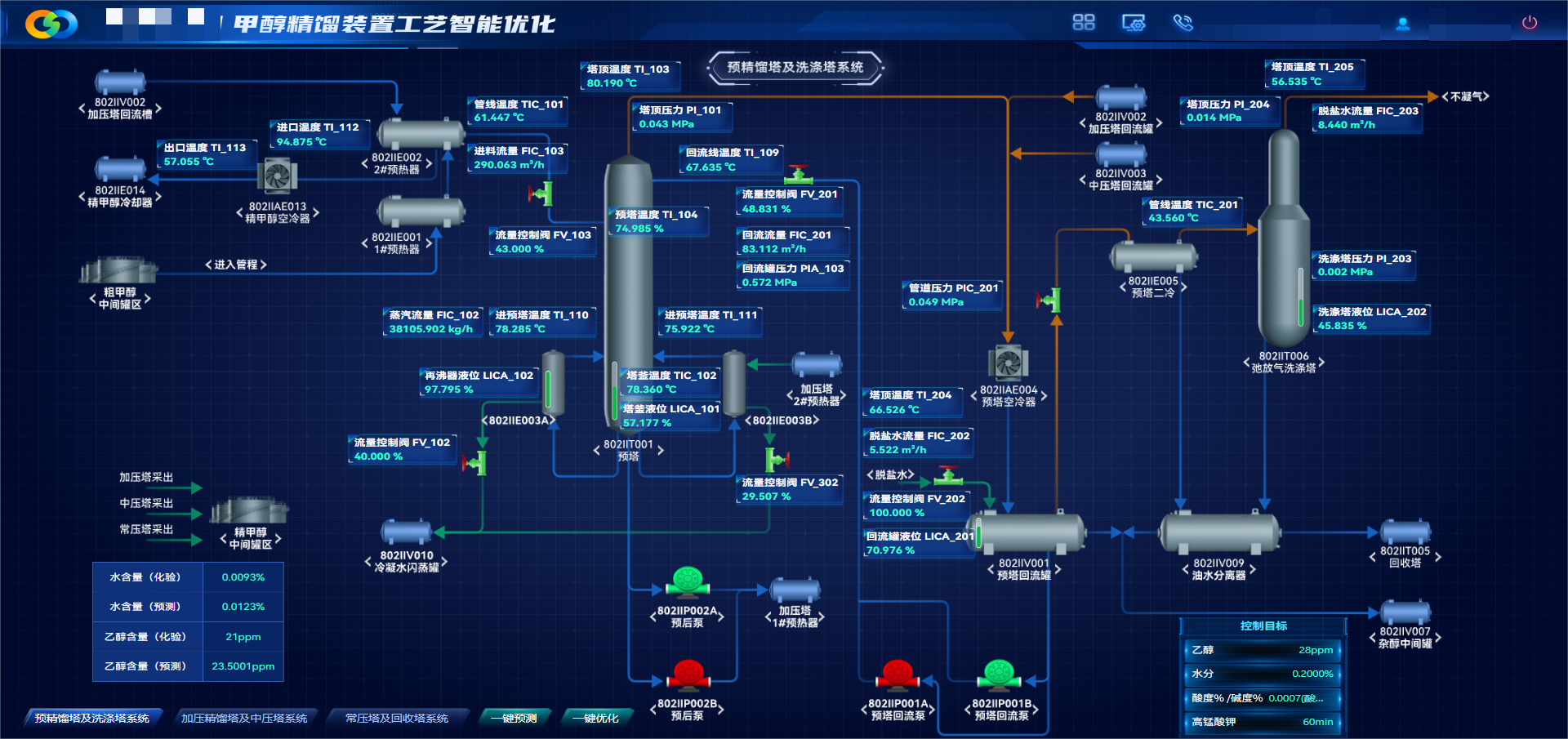
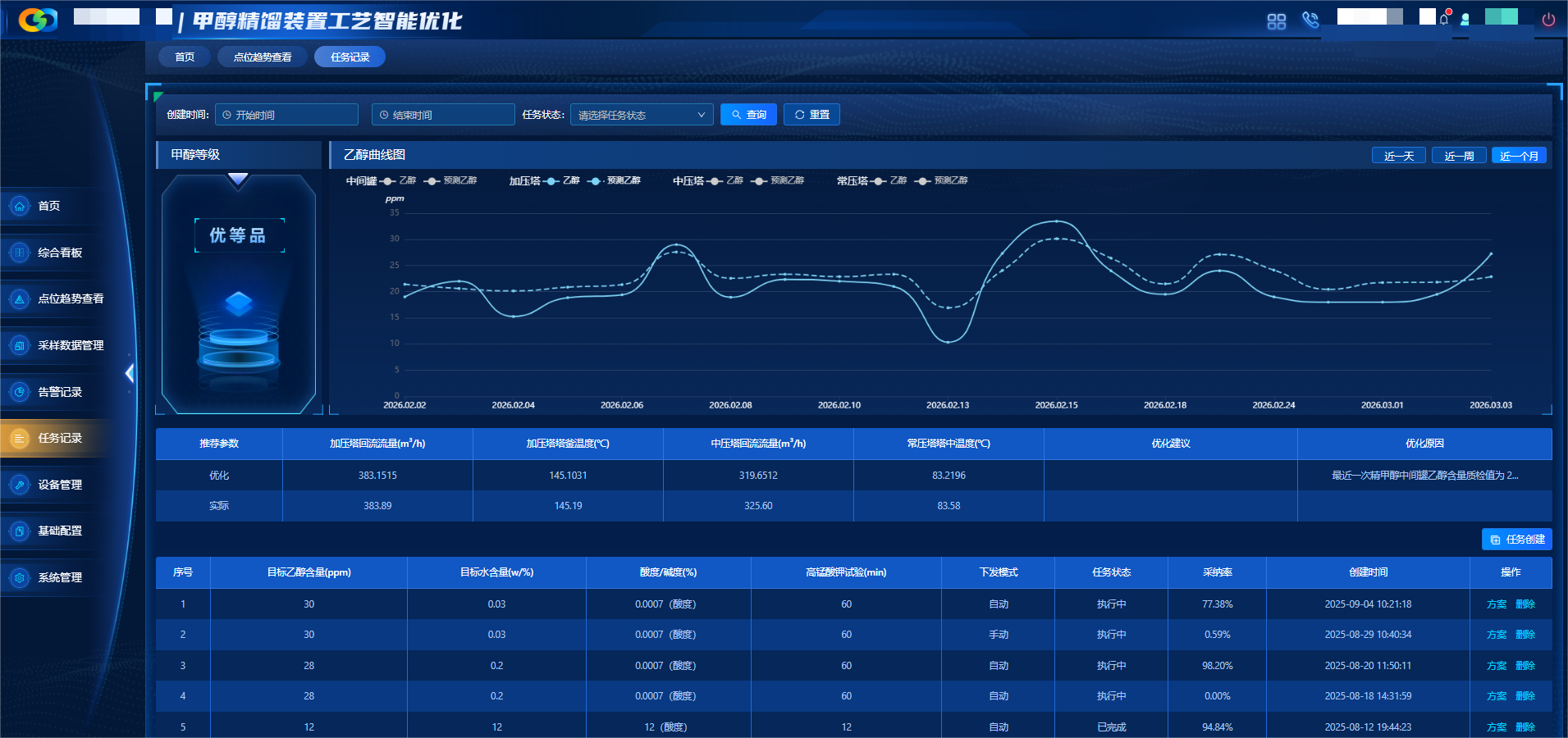
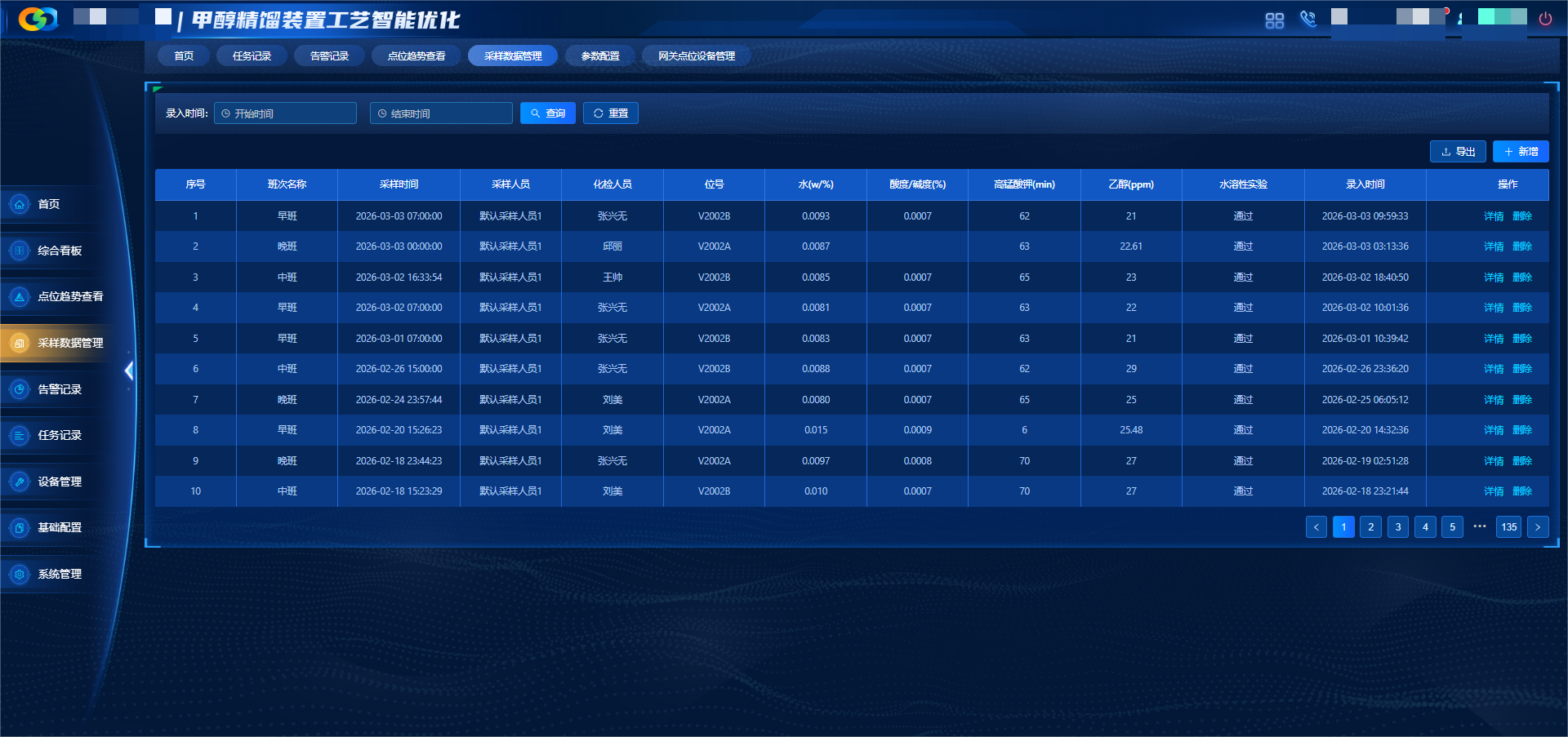
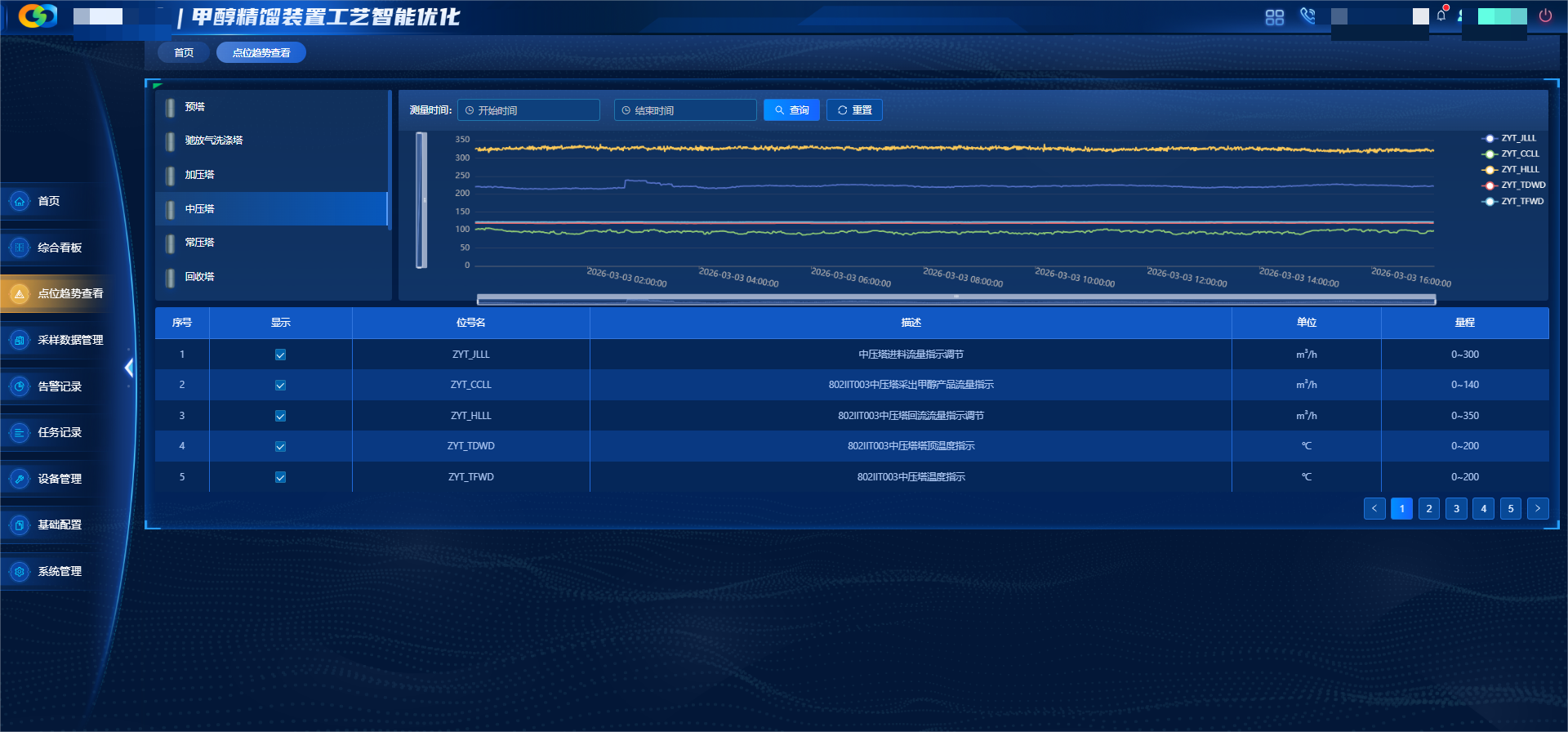
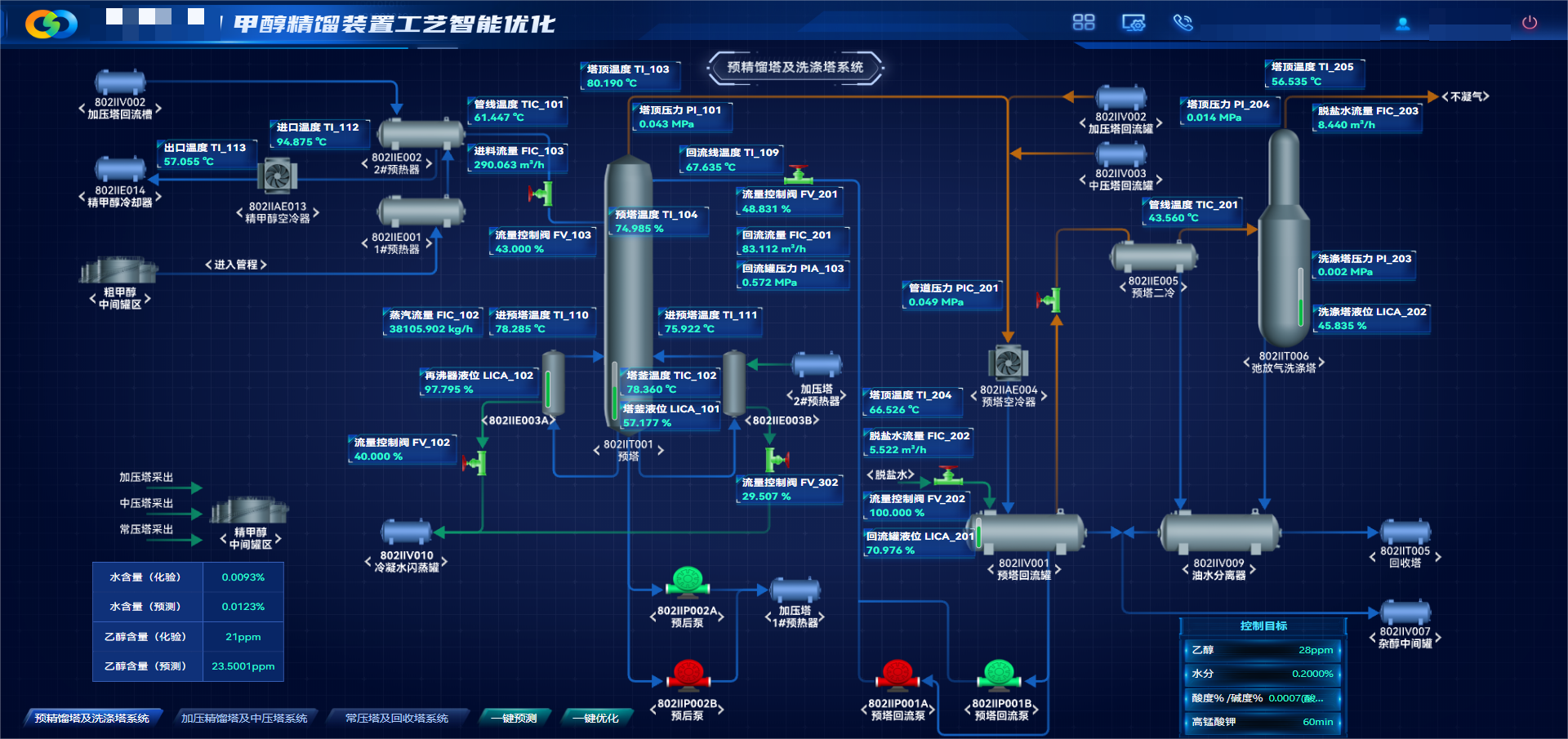
甲醇精馏高质量数据集
围绕甲醇精馏全流程构建数据集,覆盖预精馏塔、加压塔等关键单元,采集温度、压力、流量、组分等多维度时序数据,遵循全工况覆盖、高完整性、机理合规、标准统一原则,完成数据清洗、机理校验、标准化治理,提供高质量数据支撑。